
- [워드프레스] - 아이피에서 도메인으로 바꾸었을 때, 일부 리소스가 아이피를 가지고 있는 경우 2024.03.03
- [메이플스토리] - 이미지인식기반 설치기 타이머 2024.03.03
- [Terraform] - 테라폼 - vsphere provider 로 vm 생성해보기 2 2023.11.13
- [Terraform] - 테라폼 - vsphere provider 로 vm 생성해보기 1 2023.11.13
- [IaC, Terraform] - 테라폼 2023.11.10
- [백준] - 2738 - 행렬 덧셈 2023.11.02
- [백준] - 25206 - 너의 평점은 2023.11.02
- [백준] - 2941 - 크로아티아 알파벳 2023.11.01
- [백준] - 1157 - 단어공부 2023.10.31
- [백준] - 10988 - 팰린드롬인지 확인하기 2023.10.31
- [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 2023.10.30
- [백준] - 25083 - 쌔싹 2023.10.30
- [백준] - 27866 - 문자와 문자열 2023.10.30
- [백준] - 10811 - 바구니 뒤집기 2023.10.27
- [백준] - 10813 - 공바꾸기 2023.10.27
- [백준] - 5597 - 과제 안 내신 분..? 2023.10.26
- [백준] - 10810 - 공 넣기 2023.10.26
- MariaDB 설치 - CentOS7 (yum Repository) 2023.10.25
- [백준] - 10807 - 개수 세기 2023.10.25
- [백준] - 단계별 문제 풀기 현황 2023.10.23
많은 방법이 있겠지만, 플러그인이 가장 빠르고 바로 해결이 되었다.
혹시 모르니, 꼭 백업을 해놓고 시도하자.
추천하는 플러그인은 -> Velvet Blues Update URLs
설치하면, update URLs 가 있다.

누르면, 이런 페이지가 나온다.
1. Old URL 에 지금 도메인으로 바꿨는데도 남아있는 그 아이피를 http://ip:포트 형식으로 적어주고,
2. New URL 에 지금 바꾼 도메인으로 적어준다.
3. URLs in page content 이 외에 Update ALL GUIDs 를 제외하고, 다 체크 후 업데이트 해준다.


- 알람 기능 추가 F11, F12 누를시 알람 작동
- 알람 종료시 탁상시계 알림 소리
- 기능추가 : 솔 야누스 20초 때 감지 추가
- 문구수정 : 신뢰도 -> 유사도
- 유사도 기본값 수정 : 0.92 -> 0.96
- 유사도 조절 범위 수정 : 0.92 이하는 의미 없는 값으로 보고, 0.92 ~ 1.0 사이로 조절범위 변경
- 문구수정 : 딜레이 -> 감지 후 소리 지연 딜레이 (초) 로 변경
- 라디오 버튼이 더 늘어날 경우, 스킬 + 레벨 구간 + 감지 시점 (10초단위) 이렇게 변경할 예정
- 현재 정상작동하는 해상도는
- 1920x1200, 1920x1080, 1366x768, 1280x720, 1024x768
- 기본 값으로 두신 다음 실행버튼을 누르고, 사용하시면 됩니다.
- 솔 야누스는 레벨별로 쿨타임이 다르다고 하여, 오작동이 있다고 하여 나누어서 만들었습니다.
- 사운드 파일 변경(.wav 확장자)
- 신뢰도 변경
- 딜레이 변경
- 제가 야누스 8레벨 밖에 안되고, 친구는 30레벨이라 20레벨 표본이 없어 테스트는 아직 못해본 상태입니다.
- 신뢰도 : 0.92 = 92% 유사도를 만족하는 스킬을 찾습니다.
- 딜레이 : 찾는 이미지가 "10초" 라는 숫자를 포함합니다. 최소한 9초쯤에는 소리가나야하나, 사운드파일이 2초중 1초가 앞에 비어있습니다.
- ex) 딜레이값을 0 -> 8초 로 향할 수록 "늦게 알림"을 의미합니다. 사냥 스타일에 따라 편하게 조절하시면 됩니다.
- EXE 파일 생성에 사용된 모듈은 "pyinstaller" 입니다
- requirements.txt
https://drive.google.com/file/d/1Dj3GwKtRQuT9sCy3ctKLzaCrStVFrioO/view?usp=drive_link
https://drive.google.com/file/d/1dWrQlEmBLspYscLMpQJlCahwtf2AMfW3/view?usp=drivesdk
DOCS : Docs overview | hashicorp/vsphere | Terraform | Terraform Registry
Terraform Registry
registry.terraform.io
1. 프로젝트 폴더 생성 하기 - 원하는곳에 폴더 만들어서 선택
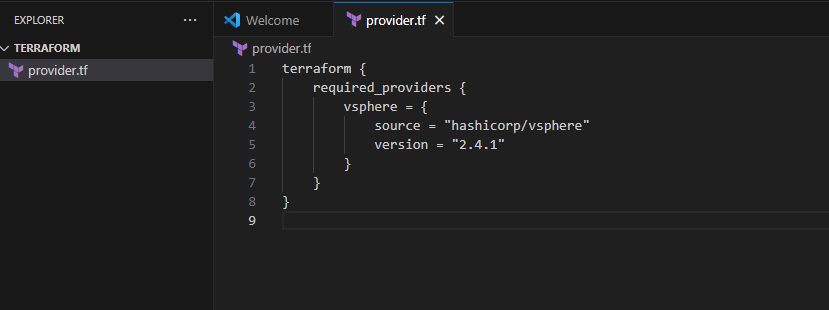
STEP 1. 폴더에 파일 만들기. provider.tf & 내용 채우기

프로바이더는 인프라 제공자를 말하며, 그 중 vsphere 를 택했다.
이유는 사내에 구성이 되있기 때문
나는 인프라 엔지니어가 아니라서, 따로 구성해본적이 없기 때문에 어쩔 수 없다.
provider.tf 에 들어갈 내용이다.
terraform {
required_providers {
vsphere = {
source = "hashicorp/vsphere"
version = "2.4.1"
}
}
}
provider "vsphere" {
user = "{vsphere.username}"
password = "{vsphere.password}"
vsphere_server = "{vsphere.address}"
allow_unverified_ssl = true
}
가장 위의 블럭은 프로바이더 제공자의 required 요소인데, 당연히 제공자 이름이 들어가야하고, 어떤 SDK 기반으로 컴파일 할 것인지 정보가 들어간다.
다음 블럭은 "프로바이더이름", vsphere 로그인정보와 주소가 들어간다.
여기서 terraform init 명령을 입력해보자.

이렇게나온다.
Initializing provider plugins.... 프로바이더와 버전에 맞는 SDK 를 다운받는 것이다.
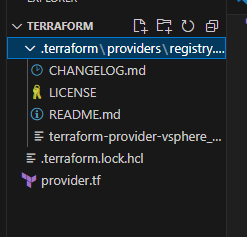
없던 파일이 생겨났다.
여기까지하면, 나는 테라폼으로 vsphere 를 제어할껀데, 필요한 sdk 를 받을꺼라는 것을 provider.tf 에 적어준것이고
terraform init 명령으로 다운받기 까지 완료한 상태이다.
STEP 2. main.tf 파일 생성후 내용 채우기
data 명령줄에는 vsphere 의 리소스 위치를 선택할 수 있다.
UI 로 따지면, 상위 카테고리에서 하위카테고리로 선택해서 들어가면서 위치와 옵션을 선택하는 과정이라 보면 된다.
resource 는 서버에서 할당할 수 있는 리소스를 의미한다.
VM 을 만든다면, 여기에 할당할 리소스들 "cpu, disk, ram, network" 등이 되겠다.
name = "실제 이름" 이 들어간다.
data "vsphere_datacenter" "datacenter" {
name = "Datacenter"
}
data "vsphere_compute_cluster" "cluster" {
name = "Arista"
datacenter_id = data.vsphere_datacenter.datacenter.id
}
data "vsphere_datastore" "datastore" {
name = "Fujitsu03"
datacenter_id = data.vsphere_datacenter.datacenter.id
}
data "vsphere_network" "network" {
name = "VM Network"
datacenter_id = data.vsphere_datacenter.datacenter.id
}
data "vsphere_virtual_machine" "template" {
name = "win2019"
datacenter_id = data.vsphere_datacenter.datacenter.id
}
resource "vsphere_virtual_machine" "vm" {
name = "win2019-terraform1"
resource_pool_id = data.vsphere_compute_cluster.cluster.resource_pool_id
datastore_id = data.vsphere_datastore.datastore.id
num_cpus = 4
memory = 8196
guest_id = data.vsphere_virtual_machine.template.guest_id
scsi_type = data.vsphere_virtual_machine.template.scsi_type
network_interface {
network_id = data.vsphere_network.network.id
adapter_type = data.vsphere_virtual_machine.template.network_interface_types[0]
}
disk {
label = "disk0"
size = data.vsphere_virtual_machine.template.disks.0.size
thin_provisioned = data.vsphere_virtual_machine.template.disks.0.thin_provisioned
}
firmware = "efi"
clone {
template_uuid = data.vsphere_virtual_machine.template.id
linked_clone = "true"
customize {
windows_options {
computer_name = "ssssss"
}
network_interface {
ipv4_address = "192.168.123.239"
ipv4_netmask = 24
}
ipv4_gateway = "192.168.123.1"
}
}
}
STEP 3. terraform apply
PS C:\Users\jaeyo\Desktop\terraform> terraform apply
data.vsphere_datacenter.datacenter: Reading...
data.vsphere_datacenter.datacenter: Read complete after 0s [id=datacenter-1001]
data.vsphere_compute_cluster.cluster: Reading...
data.vsphere_network.network: Reading...
data.vsphere_virtual_machine.template: Reading...
data.vsphere_datastore.datastore: Reading...
data.vsphere_network.network: Read complete after 0s [id=network-1016]
data.vsphere_datastore.datastore: Read complete after 0s [id=datastore-1014]
data.vsphere_compute_cluster.cluster: Read complete after 0s [id=domain-c1050]
data.vsphere_virtual_machine.template: Read complete after 0s [id=423e0473-2b46-603b-852b-c97d2d48fa85]
Terraform used the selected providers to generate the following execution plan. Resource actions are indicated with the following symbols:
+ create
Terraform will perform the following actions:
# vsphere_virtual_machine.vm will be created
+ resource "vsphere_virtual_machine" "vm" {
+ annotation = (known after apply)
+ boot_retry_delay = 10000
+ change_version = (known after apply)
+ cpu_limit = -1
+ cpu_share_count = (known after apply)
+ cpu_share_level = "normal"
+ datastore_id = "datastore-1014"
+ default_ip_address = (known after apply)
+ ept_rvi_mode = "automatic"
+ extra_config_reboot_required = true
+ firmware = "efi"
+ force_power_off = true
+ guest_id = "windows2019srv_64Guest"
+ guest_ip_addresses = (known after apply)
+ hardware_version = (known after apply)
+ host_system_id = (known after apply)
+ hv_mode = "hvAuto"
+ id = (known after apply)
+ ide_controller_count = 2
+ imported = (known after apply)
+ latency_sensitivity = "normal"
+ memory = 8196
+ memory_limit = -1
+ memory_share_count = (known after apply)
+ memory_share_level = "normal"
+ migrate_wait_timeout = 30
+ moid = (known after apply)
+ name = "win2019-terraform-20231113"
+ num_cores_per_socket = 1
+ num_cpus = 4
+ power_state = (known after apply)
+ poweron_timeout = 300
+ reboot_required = (known after apply)
+ resource_pool_id = "resgroup-1051"
+ run_tools_scripts_after_power_on = true
+ run_tools_scripts_after_resume = true
+ run_tools_scripts_before_guest_shutdown = true
+ run_tools_scripts_before_guest_standby = true
+ sata_controller_count = 0
+ scsi_bus_sharing = "noSharing"
+ scsi_controller_count = 1
+ scsi_type = "lsilogic-sas"
+ shutdown_wait_timeout = 3
+ storage_policy_id = (known after apply)
+ swap_placement_policy = "inherit"
+ tools_upgrade_policy = "manual"
+ uuid = (known after apply)
+ vapp_transport = (known after apply)
+ vmware_tools_status = (known after apply)
+ vmx_path = (known after apply)
+ wait_for_guest_ip_timeout = 0
+ wait_for_guest_net_routable = true
+ wait_for_guest_net_timeout = 5
+ clone {
+ linked_clone = true
+ template_uuid = "423e0473-2b46-603b-852b-c97d2d48fa85"
+ timeout = 30
+ customize {
+ ipv4_gateway = "192.168.123.1"
+ timeout = 10
+ network_interface {
+ ipv4_address = "192.168.123.240"
+ ipv4_netmask = 24
}
+ windows_options {
+ auto_logon_count = 1
+ computer_name = "win2019-20231113"
+ full_name = "Administrator"
+ organization_name = "Managed by Terraform"
+ time_zone = 85
}
}
}
+ disk {
+ attach = false
+ controller_type = "scsi"
+ datastore_id = "<computed>"
+ device_address = (known after apply)
+ disk_mode = "persistent"
+ disk_sharing = "sharingNone"
+ eagerly_scrub = false
+ io_limit = -1
+ io_reservation = 0
+ io_share_count = 0
+ io_share_level = "normal"
+ keep_on_remove = false
+ key = 0
+ label = "disk0"
+ path = (known after apply)
+ size = 90
+ storage_policy_id = (known after apply)
+ thin_provisioned = false
+ unit_number = 0
+ uuid = (known after apply)
+ write_through = false
}
+ network_interface {
+ adapter_type = "e1000e"
+ bandwidth_limit = -1
+ bandwidth_reservation = 0
+ bandwidth_share_count = (known after apply)
+ bandwidth_share_level = "normal"
+ device_address = (known after apply)
+ key = (known after apply)
+ mac_address = (known after apply)
+ network_id = "network-1016"
}
}
Plan: 1 to add, 0 to change, 0 to destroy.
배포가 성공하면, TEMPLATE 으로 복제 배포가 완료된다.

'ARCHIVE(완료, 보류, 관심x) > Terraform' 카테고리의 다른 글
| [Terraform] - 테라폼 - vsphere provider 로 vm 생성해보기 1 (0) | 2023.11.13 |
|---|---|
| [IaC, Terraform] - 테라폼 (0) | 2023.11.10 |
Install | Terraform | HashiCorp Developer
Install | Terraform | HashiCorp Developer
Explore Terraform product documentation, tutorials, and examples.
developer.hashicorp.com
자신의 cpu 에 맞는 걸 다운로드. (인텔꺼면 위에 암드꺼면 아래로)

압축 해제하면, 아래 파일이 나오는데

시스템 환경 변수를 잡아주어야한다.
일단, 저 파일을 C -> Terraform 폴더를 만들어서 넣어줬다.
윈도우 키를 누르고, 환경이라고 쳐보면, 시스템 환경 변수 편집이 있다.
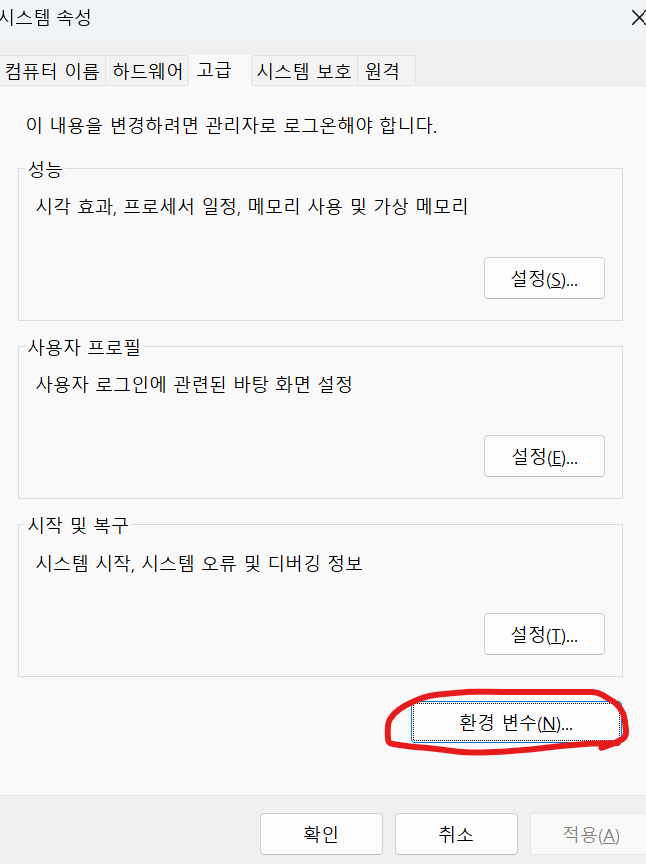



재부팅 후
cmd , powershell 등에서 terraform 이라고 쳤을 때, 아래 처럼 나오면 환경변수가 정확하게 잡힌것임.

편집기 vscode 를 설치해보자.
Download Visual Studio Code - Mac, Linux, Windows
Download Visual Studio Code - Mac, Linux, Windows
Visual Studio Code is free and available on your favorite platform - Linux, macOS, and Windows. Download Visual Studio Code to experience a redefined code editor, optimized for building and debugging modern web and cloud applications.
code.visualstudio.com

설치후 실행
Terminal 클릭 ! -> 아래 터미널 창이 열리면, terraform 입력 해보기

'ARCHIVE(완료, 보류, 관심x) > Terraform' 카테고리의 다른 글
| [Terraform] - 테라폼 - vsphere provider 로 vm 생성해보기 2 (1) | 2023.11.13 |
|---|---|
| [IaC, Terraform] - 테라폼 (0) | 2023.11.10 |
참고하면 좋은 영상
https://www.youtube.com/watch?v=3qSpwqckvXQ
테라폼이란?
테라폼(Terraform)은 하시코프(Hashicorp)에서 오픈소스로 개발중인 클라우드 인프라스트럭처 자동화를 지향하는 IaC 도구 입니다.
IaC란?
코드로서의 인프라스트럭처(Infrastructure as Code, IaC)라는 의미입니다.
코드로 인프라를 관리한다는 의미인데, 인프라에 해당하는 부분은 생각보다 많다.
대표적인 장점은
작성의 용이성
재사용성
유지보수
인프라?
서버, 미들웨어, 서비스 등이 있다.
서비스를 제공하는데 필요한 요소를 통틀어서 지칭한다고 이해하면 된다.
Terraform
테라폼은 인프라를 만들고, 변경하고, 기록하는 IaC 를 위해 만들어진 도구로써, 문법이 쉽고 사용자가 많아 자료가 많다.
.tf 의 확장자를 가지는 파일을 사용한다.
다양한 클라우드 서비스를 지원한다.
테라폼 구성요소
provider : 테라폼으로 생성할 인프라 종류
resource : 테라폼으로 실제 생성할 인프라 자원
state : 테라폼을 통해 생성한 자원의 상태
output : 테라폼으로 만든 자원을 변수 형태로 state 에 저장하는 것
module : 공통적으로 활용할 수 있는 코드를 문자 그대로 모듈 형태로 정의하는 것
remote : 다른 경로의 state 를 참조하는 것을 말함. output 변수를 불러올 때, 주로 사용
'ARCHIVE(완료, 보류, 관심x) > Terraform' 카테고리의 다른 글
| [Terraform] - 테라폼 - vsphere provider 로 vm 생성해보기 2 (1) | 2023.11.13 |
|---|---|
| [Terraform] - 테라폼 - vsphere provider 로 vm 생성해보기 1 (0) | 2023.11.13 |
Arrays.Stream으로 이차원 배열 출력하는 방법 정도는 기억해두면 좋을 것 같다.
package org.example;
import java.io.IOException;
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static void main(String[] args) throws IOException {
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int M = sc.nextInt();
int [][] matrix1 = new int[N][M];
int [][] matrix2 = new int[N][M];
int [][] result = new int[N][M];
for(int i = 0; i < N; i++){
for(int j = 0; j < M; j++){
matrix1[i][j] = sc.nextInt();
}
}
for(int i = 0; i < N; i++){
for(int j = 0; j < M; j++){
matrix2[i][j] = sc.nextInt();
}
}
for(int i = 0; i < N; i++){
for(int j = 0; j < M; j++){
result[i][j] = matrix1[i][j] + matrix2[i][j];
}
}
Arrays.stream(result).forEach(row -> {
Arrays.stream(row).forEach(value -> {
System.out.print(value + " ");
});
System.out.println();
});
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 25206 - 너의 평점은 (1) | 2023.11.02 |
|---|---|
| [백준] - 2941 - 크로아티아 알파벳 (0) | 2023.11.01 |
| [백준] - 1157 - 단어공부 (0) | 2023.10.31 |
| [백준] - 10988 - 팰린드롬인지 확인하기 (0) | 2023.10.31 |
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |

전공평점 = (학점 * 과목평점) / 학점의 총합
학점 , 등급 변환
과목, 학점, 등급을 입력받은 후
등급이 P 가 아닐 때만, 전공 학점 (학점 * 과목평점) / 학점을 누적시키면된다.
누적된 학점의 총합 (P 등급이 제외된) 과 전공 학점을 구할 수 있다.
package org.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
double totalScore = 0;
double sumOfGradeAndSubjectAveragePoint = 0;
for (int i = 0; i < 20; i++) {
String subject = "";
double score = 0;
String grade = "";
subject = sc.next();
score = sc.nextDouble();
grade = sc.next();
if(!grade.equals("P")){
sumOfGradeAndSubjectAveragePoint += majorScore(score, grade);
totalScore+= score;
}
}
double rst = result(totalScore, sumOfGradeAndSubjectAveragePoint);
System.out.println(rst);
}
public static double majorScore(double score, String grade){
// 등급 , 점수
Map<String, Double> convertTo = new HashMap<>();
convertTo.put("A+", 4.5);
convertTo.put("A0", 4.0);
convertTo.put("B+", 3.5);
convertTo.put("B0", 3.0);
convertTo.put("C+", 2.5);
convertTo.put("C0", 2.0);
convertTo.put("D+", 1.5);
convertTo.put("D0", 1.0);
convertTo.put("F", 0.0);
return score * convertTo.get(grade);
}
public static double result (double sum, double sumOfEachScore){
return sumOfEachScore / sum;
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 2738 - 행렬 덧셈 (0) | 2023.11.02 |
|---|---|
| [백준] - 2941 - 크로아티아 알파벳 (0) | 2023.11.01 |
| [백준] - 1157 - 단어공부 (0) | 2023.10.31 |
| [백준] - 10988 - 팰린드롬인지 확인하기 (0) | 2023.10.31 |
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |
시스템 입력을 String 으로 받고, 스트림으로 일단 변환했다.
스트림 API 메서드 사용하는 감을 아직 못잡겠다.
로직 자체는 떠올렸는데, 표현을 어떻게 하는지 모르겠다.
로직
필터링할 문자를 저장을 하고, 하나씩 꺼내서 입력받은 문자열요소와 순환하면서 비교후, 치환을 통해서 croatia 가 포함하지 않는 요소, 즉 a 와 같은 한글자의 문자열로 바꾼 후, String 의 길이를 출력하면 된다.
foreach 문을 통해서, List 를 순환하면서 요소를 하나씩 꺼내온다.
꺼낸 요소를 wordStream.map() 을 통해서 문자열을 치환한다.
map() 내부의 w 는 String word 의 문자열 전체를 의미하며, "helloc=" 이런 문자열을 가지고 있다면
w(helloc=).replace(list 요소, 치환 문자 a)
wordStream 은 "helloc=" 에서 -> "helloa" 로 바뀐다.
이걸 다시 wordStream 에 저장하여 모든 요소와 비교하여 치환하게 한다.
System.out::println 이런 표현도 어색해서 잘 모르겠다.
뭔가 많이 보다보니, 한번씩 시도해보게 되는데 매커니즘을 좀 더 공부해봐야겠다.
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String word = sc.nextLine();
List<String> croatia = new ArrayList<>();
croatia.add("c=");
croatia.add("c-");
croatia.add("dz=");
croatia.add("d-");
croatia.add("lj");
croatia.add("nj");
croatia.add("s=");
croatia.add("z=");
Stream<String> wordStream = Stream.of(word);
for(String croatiaElements : croatia){
wordStream = wordStream.map(w -> w.replace(croatiaElements, "a"));
}
// wordStream.forEach(System.out::println);
wordStream.forEach(w -> System.out.println(w.length()));
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 2738 - 행렬 덧셈 (0) | 2023.11.02 |
|---|---|
| [백준] - 25206 - 너의 평점은 (1) | 2023.11.02 |
| [백준] - 1157 - 단어공부 (0) | 2023.10.31 |
| [백준] - 10988 - 팰린드롬인지 확인하기 (0) | 2023.10.31 |
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |
이 문제도 풀면서 GPT 에게 물어보았다.
Stream 예제를 눈으로 많이 익히기 위해서, 먼저 시도를 해보고 물어봤는데.
처음에는 Stream.of 로 arrays 를 string 으로 바꾸려고 했는데.. new String() 이라는 쉬운 방법이 있다니 충격.
처음부터 Map 자료형을 떠올리긴 했었는데, 중복제거나 이런 부분이 머리가 아파오기 시작하면서 for 문으로 시도하였으나,
이중for 문에 if 가 들어가고, 케이스가 많아지면서 복잡해져서 포기했다.
new String(arrays) : char[] 를 String 으로 변환
chars() : String 에서 요소를 intStream 으로 변환
mapToObj(c -> (char) c ) : c 는 intStream 으로 변환된 ascii 코드의 문자 정수이며, (char) c 로 문자로 변환
filter : (Charater::isLetterOrDigit) : Charater 중에 영어문자 도는 숫자만 필터링
collect() : 스트림의 요소를 수집하여, 반환하며 어떻게 처리하고 반환할지 정의
Collectors.groupingBy() : 스트림 요소를 그룹화
Collections / Collectors 이런거 자주 사용되는데 따로 찾아봐야겠다.
package org.example;
import java.util.*;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 단어 입력 받는다.
String word = sc.nextLine().toUpperCase();
char[] arrays = word.toCharArray();
Map<Character, Long> charFrequency = new String(arrays)
.chars()
.mapToObj(c -> (char) c)
.filter(Character::isLetterOrDigit)
.collect(Collectors.groupingBy(
Character::toUpperCase,
Collectors.counting()
));
long maxFrequency = charFrequency.values().stream()
.max(Long::compare)
.orElse(0L);
String mostFrequentChars = charFrequency.entrySet().stream()
.filter(entry -> entry.getValue() == maxFrequency)
.map(entry -> entry.getKey().toString())
.collect(Collectors.joining());
if (mostFrequentChars.isEmpty() || mostFrequentChars.length() > 1) {
System.out.println("?");
} else {
System.out.println(mostFrequentChars);
}
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 25206 - 너의 평점은 (1) | 2023.11.02 |
|---|---|
| [백준] - 2941 - 크로아티아 알파벳 (0) | 2023.11.01 |
| [백준] - 10988 - 팰린드롬인지 확인하기 (0) | 2023.10.31 |
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |
| [백준] - 25083 - 쌔싹 (1) | 2023.10.30 |
역시나, 스트림 사용하는 것이 익숙하지 않고 많이 부족한 것 같다.
처음 작성한 코드는 아래와 같았다.
List<Integer> origin = spellings.boxed().collect(Collectors.toList());
List<Integer> reverse = origin;
Collections.reverse(reverse);
origin 과 reverse 를 비교해봐도, 둘의 결과가 계속 같았다.
GPT 에게 물어보았다. -> reverse = origin; 은 동일한 객체를 참조 하고 있는걸 뒤집기 때문에 문제다! 라고 했다.
원래 코드에서는 Collections.reverse(reverse);를 사용하여 reverse 리스트를 뒤집는 것이 아니라, reverse 리스트가 origin 리스트와 동일한 객체를 참조하게 됩니다. 이것은 실제로 두 리스트가 같은 데이터를 가리키기 때문에 reverse 또한 변경되면 origin도 변경됩니다.
따라서, Collections.reverse(reverse); 사용 대신에 reverse 리스트를 복제하여 origin의 역순을 만들어야 합니다. 아래는 수정된 코드에서 이것을 어떻게 수행하는지 보여줍니다:
// Create a reversed copy of the origin list
List<Integer> reverse = new ArrayList<>(origin); // Create a new list with the same elements
// Then reverse the 'reverse' list
Collections.reverse(reverse);한번, 직접 검증해보고 싶어서 테스트를 해보기로 했다.
기존코드는 서로 같은 객체를 참조한다고 리턴했다.
이 때, 서로 같은 객체는 내부의 값이 같음을 비교하는 것이 아니라
두 변수가 참조하는 객체가 동일한 주소에 있다는 것을 말한다.
이 때, == 로 비교해야하며, equals 로 비교하면 내용 비교이므로 조심해야한다.

생각을 해보았는데, 진짜 헷갈린다. 여태껏 별 생각없이 써왔으니까.
침착하게 잘생각해보면, 인스턴스를 새로 생성한것이 아니기 때문에 같은 객체를 참조하는 것이 맞다.
한동안은 체화가 되게 의식하면서 쓰도록 노력해야겠다.

풀고나서 다른 풀이를 보면, 과연 스트림을 사용하는 것이 직관적이고 편한 것은 맞는데.
복잡한 사고를 피하는 건 아닌가 싶기도하다.
package org.example;
import java.util.Collections;
import java.util.List;
import java.util.Scanner;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
//단어
String voca = sc.nextLine();
IntStream spellings= voca.chars();
List<Integer> origin = spellings.boxed().collect(Collectors.toList());
List<Integer> reverse = origin.stream()
.collect(Collectors.collectingAndThen(Collectors.toList(), list -> {
Collections.reverse(list);
return list;
}));
if(origin.equals(reverse)){
System.out.println("1");
}else{
System.out.println("0");
}
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 2941 - 크로아티아 알파벳 (0) | 2023.11.01 |
|---|---|
| [백준] - 1157 - 단어공부 (0) | 2023.10.31 |
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |
| [백준] - 25083 - 쌔싹 (1) | 2023.10.30 |
| [백준] - 27866 - 문자와 문자열 (0) | 2023.10.30 |
문제를 보면, 결국 정수의 덧셈 뺄셈 문제이다.
피스의 알맞은 갯수를 담은 배열을 1 1 2 2 2 8 이렇게 생성한다.
그 다음, 입력한 값을 각각 인덱스에서 뺀다.
package org.example;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 알맞은 세트
int[] chess_set = {1, 1, 2, 2, 2, 8};
// 체크할 세트 피스 입력
int[] chess_piece_input = new int[6];
// 결과 세트
int[] result_set = new int[6];
// 피스 갯수 입력
for(int i = 0 ; i < chess_set.length; i++){
chess_piece_input[i] = sc.nextInt();
}
// 연산 : set - piece
for(int i = 0; i < chess_set.length; i++){
result_set[i] = chess_set[i] - chess_piece_input[i];
}
// 결과 출력
for (int x : result_set
) {
System.out.print(x + " ");
}
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 1157 - 단어공부 (0) | 2023.10.31 |
|---|---|
| [백준] - 10988 - 팰린드롬인지 확인하기 (0) | 2023.10.31 |
| [백준] - 25083 - 쌔싹 (1) | 2023.10.30 |
| [백준] - 27866 - 문자와 문자열 (0) | 2023.10.30 |
| [백준] - 10811 - 바구니 뒤집기 (0) | 2023.10.27 |
솔직히 이런문제 너무 별론거같다.

public class Main {
public static void main(String[] args) {
System.out.println(" ,r'\"7");
System.out.println("r`-_ ,' ,/");
System.out.println(" \\. \". L_r'");
System.out.println(" `~\\/");
System.out.println(" |");
System.out.println(" |");
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 10988 - 팰린드롬인지 확인하기 (0) | 2023.10.31 |
|---|---|
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |
| [백준] - 27866 - 문자와 문자열 (0) | 2023.10.30 |
| [백준] - 10811 - 바구니 뒤집기 (0) | 2023.10.27 |
| [백준] - 10813 - 공바꾸기 (1) | 2023.10.27 |
String.substring();
package org.example;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 단어 입력
String voca = sc.nextLine();
// 단어의 N 번째 스펠링
int seletedOfSpell = sc.nextInt();
String selected = voca.substring(seletedOfSpell-1, seletedOfSpell);
System.out.println(selected);
}
}String.charAt();
package org.example;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 단어 입력
String voca = sc.nextLine();
// 단어의 N 번째 스펠링
int seletedOfSpell = sc.nextInt();
char vocaArray = voca.charAt(seletedOfSpell-1);
System.out.println(vocaArray);
}
}String.toCharArray();
package org.example;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 단어 입력
String voca = sc.nextLine();
// 단어의 N 번째 스펠링
int seletedOfSpell = sc.nextInt();
char[] result = voca.toCharArray();
System.out.println(result[seletedOfSpell-1]);
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 3003 - 킹, 퀸, 룩, 비숍, 나이트, 폰 (0) | 2023.10.30 |
|---|---|
| [백준] - 25083 - 쌔싹 (1) | 2023.10.30 |
| [백준] - 10811 - 바구니 뒤집기 (0) | 2023.10.27 |
| [백준] - 10813 - 공바꾸기 (1) | 2023.10.27 |
| [백준] - 5597 - 과제 안 내신 분..? (0) | 2023.10.26 |
조금 어려웠다.
버블정렬을 잘 쓸일이 없다보니, 할 때마다 복잡하게 느껴지고 불편했다.
그래서, 다른 방법이 없을까 고민했다.
1. 문제에서 필요한 스킬은 원하는 크기의 배열 생성
2. 배열에 값을 할당
3. 할당된 값을 특정 부분만 리버스 정렬하여
* 크기를 비교를 하는지, 단순히 자리만 바꾸는지는 문제에 따라서 다르겠지만 넋놓고 풀면 틀릴것 같다.
1. int array 로 값을 저장한다음, 스트림을 통해서 리스트로 변환해준다.
(변환한 이유는 Collections.reverse() 를 사용하기 위해서 래퍼타입으로 변환해줬다.
그리고, subList() 를 사용하여, reverse 할 범위를 지정할 수 있기 때문에 해볼만한 방법이라 생각했다.)
2. 원본을 복사하여 카피본을 저장한다
3. subList를 통해서 범위를 지정해서 자른다.
4. Collections.reverse(subList) 로 역정렬한다.
5. subList(시작, 끝) 을 사용했기 때문에 정확한 인덱스를 알고 있다
6. 원본인덱스에 맞게 덮어쓴다.
package org.example;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int basketCount = sc.nextInt();
int countOfReverse = sc.nextInt();
int[] basket = new int[basketCount];
// 바구니를 생성
for(int i = 0 ; i < basketCount; i ++){
basket[i] = i + 1;
}
// System.out.println(Arrays.stream(basket));
// Reverse
List<Integer> result = new ArrayList<>();
for (int i = 0 ; i < countOfReverse; i++) {
int indexOfFrom = sc.nextInt() - 1;
int indexOfTo = sc.nextInt() - 1;
// System.out.println("from : " + (indexOfFrom+ 1) + " to : " + (indexOfTo + 1) );
List<Integer> list = Arrays
.stream(basket)
.boxed()
.collect(Collectors.toList());
List<Integer> copy = list;
// System.out.println("start : " + indexOfFrom + " end : " + indexOfTo);
copy = copy.subList(indexOfFrom, indexOfTo + 1);
Collections.reverse(copy);
// System.out.println("copy reverse : " + copy);
int count = 0;
for(int j = indexOfFrom ; j < indexOfTo + 1; j ++){
basket[j] = copy.get(count);
count ++;
}
}
for(int out : basket){
System.out.print(out + " ");
}
}
}
'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 25083 - 쌔싹 (1) | 2023.10.30 |
|---|---|
| [백준] - 27866 - 문자와 문자열 (0) | 2023.10.30 |
| [백준] - 10813 - 공바꾸기 (1) | 2023.10.27 |
| [백준] - 5597 - 과제 안 내신 분..? (0) | 2023.10.26 |
| [백준] - 10810 - 공 넣기 (0) | 2023.10.26 |
주의할 부분은 인덱스 실수 하지 않기.
package org.example;
import java.util.*;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 바구니 갯수
int basketSize = sc.nextInt();
int[] basket = new int[basketSize];
// 공 바꿀 횟수
int swapCount = sc.nextInt();
int temp, source, target;
// 바구니 초기화 (공 셋팅)
for (int i = 1; i <= basketSize; i++){
basket[i-1] = i;
}
// 스왑정보를 받을 인풋 호출 횟수
for(int i = 0; i < swapCount; i++){
// 바꿀공이 들어있는 바구니 번호 입력
source = sc.nextInt() - 1;
target = sc.nextInt() - 1;
// 입력받은 바구니 번호를 토대로 스왑정렬로 교환
temp = basket[source ];
basket[source ] = basket[target];
basket[target] = temp;
}
for (int out : basket
) {
System.out.print(out + " ");
}
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 27866 - 문자와 문자열 (0) | 2023.10.30 |
|---|---|
| [백준] - 10811 - 바구니 뒤집기 (0) | 2023.10.27 |
| [백준] - 5597 - 과제 안 내신 분..? (0) | 2023.10.26 |
| [백준] - 10810 - 공 넣기 (0) | 2023.10.26 |
| [백준] - 10807 - 개수 세기 (0) | 2023.10.25 |
문제를 읽어보면, 차집합을 구하는 문제이다.
전체 U, 과제를 낸 집단을 A 라 했을 때,
U - A 를 구하는 문제.
Stream 을 잘 다룰줄 몰라서, 챗 GPT 에게 물어보았다.
- 스트림 API와의 호환성: 스트림 API는 기본 자료형(primitive types)에 대한 연산을 수행할 수 있도록 여러 메소드를 제공합니다. 그러나 배열을 스트림으로 변환할 때 기본 자료형 배열은 직접적으로 스트림으로 변환할 수 없습니다. 따라서 boxed()를 사용하여 기본 자료형을 래퍼 클래스로 변환하면 스트림 API를 활용할 수 있습니다.
package org.example;
import java.util.*;
import java.util.function.Predicate;
import java.util.stream.Collectors;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int[] submitted = new int[28];
int[] all = new int[30];
for (int counter = 0; counter < 28; counter++) {
submitted[counter] = sc.nextInt();
}
for (int counter = 0; counter < 30; counter++) {
all[counter] = counter + 1;
}
List<Integer> allList = Arrays.stream(all)
.boxed()
.collect(Collectors.toList());
List<Integer> difference = new ArrayList<>(allList);
difference.removeAll(Arrays.stream(submitted)
.boxed()
.collect(Collectors.toList()));
for (int print : difference) {
System.out.println("x: " + print);
}
}
}List<Integer> allList = ...
Arrays.stream(all) 은 int[] 타입의 all 을 스트림으로 변환한다.
컬렉션API 를 사용하려면, Primitive 타입은 다룰수가 없기에 Wrapper Class 로 변환해준다.
이것을 박싱이라고 표현한다.
그 것을 처리해주는 메서드가 boxed()이다.
List<Integer> difference = ...
Arrays.stream(submitted) 는 int[] 타입 submitted 를 스트림으로 변환한다.
그다음 래퍼클래스로 박싱해준다.
마지막으로 difference (all) 에서 removeAll() 을 사용하여, 괄호안의 요소를 제거할 수 있다.
'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 10811 - 바구니 뒤집기 (0) | 2023.10.27 |
|---|---|
| [백준] - 10813 - 공바꾸기 (1) | 2023.10.27 |
| [백준] - 10810 - 공 넣기 (0) | 2023.10.26 |
| [백준] - 10807 - 개수 세기 (0) | 2023.10.25 |
| [백준] - 단계별 문제 풀기 현황 (0) | 2023.10.23 |
문제를 이해하는데서 헷갈리는 부분이 많았다.
본능적으로 반복문 횟수를 정하는 요소를 찾아야 한다는 생각은 있었는데,
잘보이지 않았다. 바구니 갯수를 반복해야할까? M번 공을 넣으려고 한다는 말을 아예 뺏으면 안헷갈렸을 것 같다.
M번이 횟수인지, 번호인지 혼동이 왔다.
뒷부분만 읽어보면 M 의 번호를 가진 공인걸 알 수 있다.
또 혼동된 부분은 가장 처음 바구니에는 공이 들어있지 않으며 라는 말?
모든 바구니가 비어있다는 말과는 다르기 때문에 이 부분을 어떻게 봐야하나 싶다.
그럼 결과 값은 0 으로 항상 시작해야하는 것 아닌가?
사실 이부분은 아무리 봐도 모르겠다...
arrayOfBasket[i - 1] 은 솔직히 0 1 2 1 1 이렇게 나와서 한칸 밀어버린건데
문해력이 부족한건지원..


import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// baskets
int numberOfBaskets = sc.nextInt();
int[] arrayOfBaskets = new int[numberOfBaskets];
// ball
int numberOfBalls = sc.nextInt();
int i, j ,k;
// 공을 N 번 넣을 예정이니까 공번호 시작 1 번 ~
for (int startAt = 0; startAt < numberOfBalls; startAt++) {
// 바구니 선택 범위와 공번호를 지정
i = sc.nextInt();
j = sc.nextInt();
k = sc.nextInt();
// 바구니에 공을 넣어 보기
while(i <= j){
arrayOfBaskets[i - 1] = k;
i++;
}
}
for (int print : arrayOfBaskets
) {
System.out.println(print);
}
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 10813 - 공바꾸기 (1) | 2023.10.27 |
|---|---|
| [백준] - 5597 - 과제 안 내신 분..? (0) | 2023.10.26 |
| [백준] - 10807 - 개수 세기 (0) | 2023.10.25 |
| [백준] - 단계별 문제 풀기 현황 (0) | 2023.10.23 |
| [백준] - 25314 - 코딩은 체육과목 입니다 (0) | 2023.10.23 |
주소 : https://mariadb.org/download/?t=repo-config&d=CentOS+7&v=10.11&r_m=blendbyte

설치 페이지에서 Repository 를 찾아들어간 후,
vi /etc/yum.repos.d/MariaDB.repo 로 yum 레포지토리 등록해주기
# MariaDB 10.11 CentOS repository list - created 2023-10-25 04:53 UTC
# https://mariadb.org/download/
[mariadb]
name = MariaDB
# rpm.mariadb.org is a dynamic mirror if your preferred mirror goes offline. See https://mariadb.org/mirrorbits/ for details.
# baseurl = https://rpm.mariadb.org/10.11/centos/$releasever/$basearch
baseurl = https://tw1.mirror.blendbyte.net/mariadb/yum/10.11/centos/$releasever/$basearch
module_hotfixes = 1
# gpgkey = https://rpm.mariadb.org/RPM-GPG-KEY-MariaDB
gpgkey = https://tw1.mirror.blendbyte.net/mariadb/yum/RPM-GPG-KEY-MariaDB
gpgcheck = 1
설치 명령어
sudo yum install MariaDB-server MariaDB-client
* 에러 발생시 (Require pv) 아래 명령어를 추가로 입력

실행 방법
데몬 실행
systemctl start mariadb
패스워드 설정
/usr/bin/mysqladmin -u root password
로그인
mysql -u root -p
부팅시 자동 시작
systemctl enable mariadb
Int 형 Array 를 Stream 으로 변환하여, 필터를 통해서 입력한 숫자와 같은 숫자를 필터링 한다.
후에 카운팅을 하고, Long 을 반환하기 때문에, int 형으로 캐스팅 해주었다.
package org.example;
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
int[] inputArray = new int[N];
for(int i = 0; i <= N - 1; i++){
inputArray[i] = sc.nextInt();
}
int searchNum = sc.nextInt();
int count = (int) Arrays.stream(inputArray).filter(value -> value == searchNum).count();
System.out.println(count);
}
}'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 5597 - 과제 안 내신 분..? (0) | 2023.10.26 |
|---|---|
| [백준] - 10810 - 공 넣기 (0) | 2023.10.26 |
| [백준] - 단계별 문제 풀기 현황 (0) | 2023.10.23 |
| [백준] - 25314 - 코딩은 체육과목 입니다 (0) | 2023.10.23 |
| [백준] - 25304 - 영수증 (0) | 2023.10.23 |

'AREA(지속적인 일상) > 02_백준' 카테고리의 다른 글
| [백준] - 10810 - 공 넣기 (0) | 2023.10.26 |
|---|---|
| [백준] - 10807 - 개수 세기 (0) | 2023.10.25 |
| [백준] - 25314 - 코딩은 체육과목 입니다 (0) | 2023.10.23 |
| [백준] - 25304 - 영수증 (0) | 2023.10.23 |
| [백준] - 2480 주사위 세개 (0) | 2023.10.23 |